'경사하강법'에 해당되는 글 2건
- 2019.11.21 :: [파이썬, 텐서플로우] 단순회귀분석 (Simple Regression Analysis) 2
- 2019.11.06 :: 범주형 데이터 선형회귀 분석하기 2
단순회귀분석(Simple Regression Analysis)
회귀분석이란 변수 사이의 인과관계를 증명하는 방법으로 단순회귀분석, 다중회귀분석, 로지스틱 회귀분석 등과 같이 종류가 다양합니다.
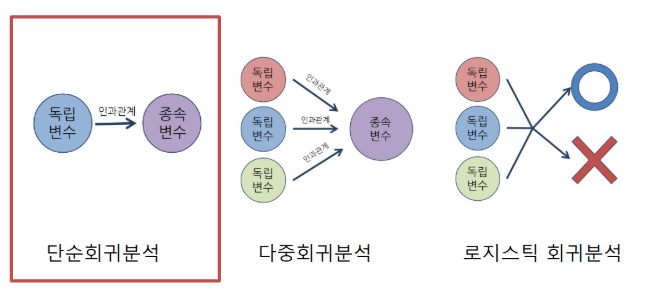
그 중에서 단순회귀분석은 하나의 독립변수(설명변수)와 하나의 종속변수(반응변수)에 대한 회귀분석을 말합니다.
이 블로그에서는 statsmodels 패키지를 사용하여 회귀분석한 것과, 텐서플로우를 사용하여 회귀분석한 것을 둘 다 해보겠습니다.
우선 statsmodels를 사용하여, 단순회귀분석을 구현해보겠습니다.
필요패키지를 가져옵니다.
import pandas as pd
import statsmodels.formula.api as sm
그 다음 데이터를 불러옵니다. 저는 가상의 데이터를 불러오겠습니다.
df = pd.read_csv('simpledata.csv')
이제 회귀 분석을 합니다.
model = sm.ols(formula = 'v2 ~ v1', data = df).fit()
model.summary()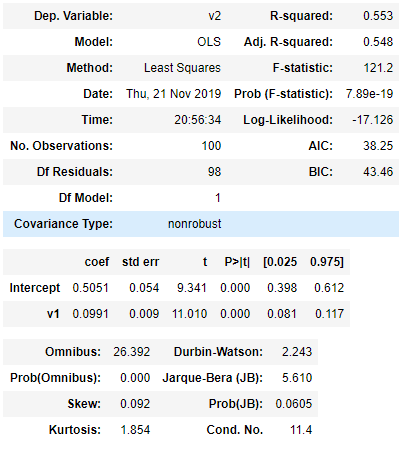
과정에 따라 다르게 적용되지만 적용 기준이 없을 경우, 일반적으로 p값(P>|t| , 유의확률)이 0.05가 넘으면 무의미한 변수라고 하며 단순회귀분석을 할 수 없습니다. Adj.R-squared 는 조정 결정 계수로 0과 1사이에 있으며, 종속 변수와 독립변수 사이에 상관관계(인과관계가 아닙니다)가 높을수록 1에 가까워집니다.
예시로 만든 그림을 보면 회귀식은 y(hat)=0.0991*v1+0.5051 으로 나오며, 만약 v1의 값이 1이라면 v2의 값은 0.6042라고 예측합니다.
이제 텐서플로우에서 단순회귀분석을 구현해보겠습니다.
필요패키지를 불러옵니다.
import pandas as pd
import numpy as np
import tensorflow as tf
import os
그 다음 데이터를 불러옵니다. 위에서 사용한 데이터를 다시 불러오겠습니다.
df = pd.read_csv('simpledata.csv')
그 후, 두 변수를 다루기 편하도록, 넘파이 행렬로 변환합니다.
data_y = np.array(df.v2)
data_x = np.array(df.v1)
이제 본격적으로 텐서플로우를 사용하겠습니다.
우선, simplesimple_regresstion 이라는 이름을 가진 그래프를 그립니다.
그 후, 외부데이터를 받아서 저장하는 변수인 placeholder를 그래프에 2개 추가합니다.
다음으로 상수를 정의하는 constant를 그래프에 추가합니다.
학습 중에 계속 변하는 변수인 get_variable을 두 개 추가시킵니다.
여기까지가 선형회귀에 필요한 변수입니다.
그 다음으로는 오차를 지정해주며, 이 오차를 줄이기위해 저는 경사하강법(GradientDescent Algorithm)을 사용하였습니다.
with tf.Graph().as_default() as simple_regresstion:
X = tf.placeholder(tf.float32, [None], name='X')
Y = tf.placeholder(tf.float32, [None], name='Y')
lr = tf.constant(1e-3,tf.float32)
W = tf.get_variable("W",dtype=tf.float32,initializer=tf.constant(1.,tf.float32))
b = tf.get_variable("b",dtype=tf.float32,initializer=tf.constant(1.,tf.float32))
h = W*X + b
cost = tf.reduce_mean(tf.square(tf.subtract(h,Y)))
train = tf.train.GradientDescentOptimizer(lr).minimize(cost)
여기까지가 그래프를 그리는 과정입니다.
이제 Session을 사용하여 방금 만든 그래프를 불러와 학습을 시킵니다.
with tf.Session(graph = simple_regresstion) as sess:
sess.run(tf.global_variables_initializer())
for i in range(2000):
_,l = sess.run([train,cost],feed_dict={X:data_x,Y:data_y})
print("cost",l)
weight, bias = sess.run([W,b])
print(weight, bias)range에 있는 숫자를 변화시켜 학습횟수를 변경시킬 수 있습니다.
print("cost",1) 를 통해 오차가 줄어드는 것을 확인할 수 있으며, print(weight, bias)를 통해 회귀계수를 확인할 수 있습니다.
print(weight*1+bias)
예시 데이터로 v1에 1을 넣었을 때, v2는 0.7041902616620064가 나왔습니다.
이제 텐서플로우로 만든 회귀식을 그래프로 그려보겠습니다.
필요패키지입니다.
import matplotlib.pyplot as plt
그래프를 그리는 코드입니다.
plt.scatter(data_x,data_y)
plt.plot(data_x,data_x*weight+bias,'r')
plt.show()
찍힌 점들은 실제 데이터 점이며, 그어진 직선이 단순선형회귀를 통해 구해진 모델입니다.
'Python 파이썬 > 머신러닝' 카테고리의 다른 글
| 군집 분석 (클러스터 분석) (0) | 2019.11.12 |
|---|---|
| K-최근접 이웃 알고리즘 (KNN) 간단한 파이썬 코드 (0) | 2019.11.11 |
| K-최근접 이웃 알고리즘 (KNN) (0) | 2019.11.11 |
| 범주형 데이터 선형회귀 분석하기 (2) | 2019.11.06 |
| 넘파이 NumPy (0) | 2019.10.11 |
아는 사람이 졸업작품으로 '날씨에 따른 중국집 배달 수를 조사'하고 싶다고 하여서 참고하라고 만들어보았습니다.
우선 필요할 듯한 패키지입니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import matplotlib.ticker as plticker
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import os
import tensorflow as tf
import statsmodels.formula.api as sm
from patsy import dmatrices
지인의 데이터를 확인하지 못하여 임의로 만들었습니다.
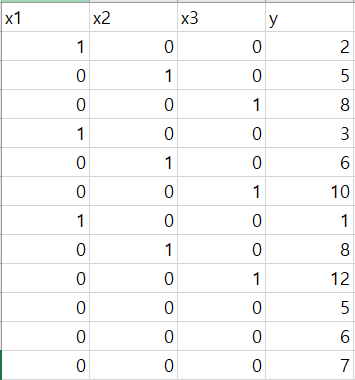
x1 x2 x3
1 0 0 - 맑음
0 1 0 - 흐림
0 0 1 - 비
0 0 0 - 눈
순위가 정해지지 않은 범주형 데이터를 분석할 때에는 변수를 위와 같이 만들어야합니다.
일단 데이터를 불러옵니다.
data = pd.read_csv('data.csv')
model = sm.ols(formula = 'y ~ x1 + x2 + x3',data=data).fit()
model.summary()
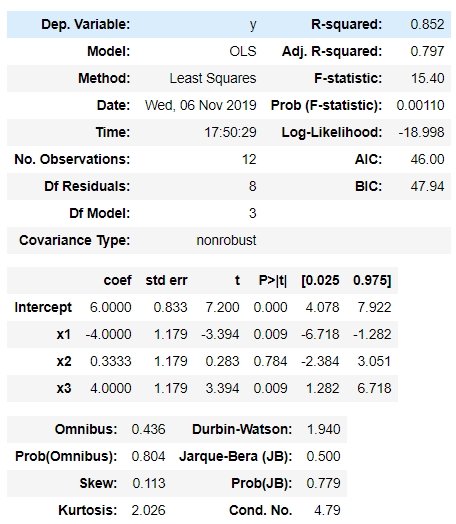
선형회귀표입니다.
P>|t| 가 0.05 보다 높으면 쓸모 없는 변수이지만, x1,x2,x3는 날씨라고 하는 한 변수의 더미변수이기 때문에 전부 버려야하는 상황이 아니면 버리지 않습니다.
Adj.R-squared 는 수정된 상관관계입니다. 실제로 종속변수에 영향을 주는 독립변수들에 의해 설명되는 분산의 비율을 알려줍니다. 이번 블로그의 주제인 '날씨에 따른 중국집 배달 수를 조사'는 사회과학에 속하기에 시계열, 패널 데이터가 아닌 이상 결정계수가 낮을 가능성이 매우 크지만, 적절한 추정방법을 사용했다면 작더라도 상관은 없습니다.
다루기 편하게 x와 y를 NumPy 배열로 변경합니다.
multi_y = np.array(data.y)
df_x = data[["x1", "x2", "x3"]]
multi_x = df_x.as_matrix()
그 다음부터는 본격적으로 tensorflow를 사용하겠습니다.
with tf.Graph().as_default() as multi_regresstion:
num_x = 3 # x변수는 몇개?
X = tf.placeholder(tf.float32, [None, num_x], name='X')
Y = tf.placeholder(tf.float32, [None], name='Y')
lr = tf.constant(1e-3,tf.float32)
W = tf.get_variable("W", [1,num_x], tf.float32)
b = tf.get_variable("b",dtype=tf.float32,initializer=tf.constant(1.,tf.float32))
h = tf.matmul(W,X,transpose_b=True) + b
cost = tf.reduce_mean(tf.square(tf.subtract(h,Y)))
train = tf.train.GradientDescentOptimizer(lr).minimize(cost)우선 multi_regresstion이라는 이름을 가진 그래프를 만듭니다.
그후 placeholder 2개를 그래프에 추가합니다. placeholder는 외부데이터를 받아서 저장하는 변수로,
tf.placeholder(자료형, 텐서모양,이름)으로 구성됩니다.
tf.constant는 상수를 정의해주며, tf.constant(값, 자료형)으로 구성됩니다.
tf.get_variable은 학습 중에 계속 변하는 변수이며, tf.get_variable(이름,자료형,초기값)으로 구성됩니다.
여기까지가 선형회귀에 필요한 변수입니다.
cost는 계산할 오차이며, 이 오차를 줄이기 위해 GradientDescent알고리즘을 이용하였습니다.
이제 그래프 그리기는 모두 끝났으며, Session을 사용하여 방금 만든 그래프를 불러옵니다.
with tf.Session(graph=multi_regresstion) as sess:
sess.run(tf.global_variables_initializer())
for i in range(3000):
_,l = sess.run([train,cost],feed_dict={X:multi_x,Y:multi_y})
print("loss",l)
W_multi, b_multi = sess.run([W,b])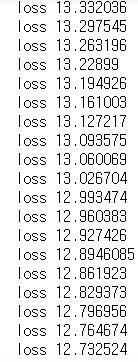
학습을 진행할 수록 loss(cost)가 줄어드는 것을 볼 수 있습니다. (만약 NA값이 뜨거나 점점 커지면 식의 설명력이 너무 낮아서 변수를 바꾸거나 다른 방법을 써야 합니다. 이건 나중에 쓸 일이 있으면 올리겠습니다.)
for j in range(len(multi_x)):
sum = 0
for i in range(3):
sum += W_multi[0][i] * multi_x[j,i]
print(multi_y[j],sum+b_multi)
print(W_multi,b_multi)
이제 학습을 마쳤으니 결과를 확인할 차례입니다.

실행시에 위와 비슷한 결과가 나옵니다.
결과적으로
h = -2.593823*x1 + 1.0692451*x2 + 3.6352885*x3 + 5.5272436
라는 식을 얻을 수 있습니다.
def weather(weather):
if weather == '맑음':
a,b,c = 1,0,0
elif weather == '흐림':
a,b,c = 0,1,0
elif weather == '비':
a,b,c = 0,0,1
elif weather == '눈':
a,b,c = 0,0,0
else:
a,b,c = 'error'
d = W_multi[0][0]*a+W_multi[0][1]*b+W_multi[0][2]*c+b_multi
return(a,b,c,d)
이제 새로운 값을 얻었을 경우 값 예측을 만들면 됩니다.
weather('눈')
'Python 파이썬 > 머신러닝' 카테고리의 다른 글
| 군집 분석 (클러스터 분석) (0) | 2019.11.12 |
|---|---|
| K-최근접 이웃 알고리즘 (KNN) 간단한 파이썬 코드 (0) | 2019.11.11 |
| K-최근접 이웃 알고리즘 (KNN) (0) | 2019.11.11 |
| 넘파이 NumPy (0) | 2019.10.11 |
| 머신러닝의 개념 (0) | 2019.10.09 |