'알고리즘'에 해당되는 글 2건
- 2019.11.13 :: AI튜터 출시, AI기술로 영어 공부
- 2019.11.11 :: K-최근접 이웃 알고리즘 (KNN) 간단한 파이썬 코드
뉴스 출처입니다~ 자세한 내용은 밑의 기사에서 확인해주세요^^
(http://www.aitimes.com/news/articleView.html?idxno=121321)
캐럿글로벌-LG CNS 'AI튜터' 출시..."AI기술로 영어 공부" - AI타임스
(AI타임스=이혜진 기자) AI와 외국어 교육 분야를 접목시킨 서비스, ‘AI TUTOR’ 서비스가 올 하반기 본격 출시를 앞두고 있다.LG CNS와 ㈜캐럿글로벌과이 준비한 ‘AI TUTOR(이하 AI튜터)’는 LG CNS의 AI기술...
www.aitimes.com
AI와 외국어 교육 분야를 접목시킨 AI튜터 서비스가 올 하반기에 출시한다고 합니다.
관계자에 따르면 음성 AI 기술과 문장 유사도 알고리즘을 활용하여 비즈니스, 일상 상황 영어를 대화형 UX로 시공간의 제약 없이 스스로 학습할 수 있는 트레이닝 서비스라고 합니다.
문장 유사도 알고리즘
워드투벡터(Word2Vec)
단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터화하는 방법이 필요합니다. 그리고 이를 위해 사용되는 대표적인 방법이 워드투백터(Word2Vec)입니다.
Word2Vec에는 CBOW(Continuous Bag of Words)와 Skip-Gram 두 가지 방식이 있습니다.
CBOW는 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법입니다.
Skip-Gram은 중간에 있는 단어로 주변 단어들을 예측하는 방법입니다. 메커니즘 자체는 CBOW와 거의 동일합니다.
글로브(GloVe)
글로브는 카운트 기반과 예측 기반을 모두 사용하는 방법론입니다. 예측 기반의 Word2Vec의 단점을 보완한다는 목적으로 나왔으나 현재까지의 연구에 따르면 두 개 중 어느 것이 더 우수하다고 할 수 없다고 합니다.
'기타 > IT 관련 뉴스 기사수집' 카테고리의 다른 글
| BNK·DGB·JB금융, 빅데이터 플랫폼 구축…‘디지털 전환’ 가속 (0) | 2020.05.20 |
|---|---|
| ‘삼성 AI 포럼 2019’ 기술 한계 극복을 위해 글로벌 전문가 한 자리에 (0) | 2019.11.14 |
| 연주자 감성까지 반영하는 '음악AI'연구 (0) | 2019.11.11 |
| 대학생에게 홈쇼핑 데이터를 주면 매출을 예측할 수 있을까? (0) | 2019.11.08 |
| 더존비즈온, '위하고' 기반으로 이커머스 사업 진출 (0) | 2019.11.07 |
이론 부분은 전편에서 확인해주세요(https://sno-machinelearning.tistory.com/61)
K-최근접 이웃 알고리즘 (KNN)
K-최근접 이웃 알고리즘은 특정 공간 내에서 입력과 가장 근접한 K개의 요소를 찾아서 더 많이 일치하는 것으로 분류하는 알고리즘으로 가장 간단한 기계학습 알고리즘입니다. 그림으로 살펴보도록 하겠습니다...
sno-machinelearning.tistory.com
KNN알고리즘을 파이썬으로 간단하게 표현했습니다.
우선 필요 패키지부터 불러옵니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt그 후 데이터를 불러옵니다. (데이터는 네이버의 2019년 자동차 데이터 중 일부를 가져왔습니다.)
data = pd.read_csv('cars.csv', encoding="euc-kr")
data.city_mpg = data.city_mpg*10 # 변수끼리 간단하게나마 비율을 맞추었습니다.
df_z = np.array(data.fuel)
df_xy = data[["hp", "city_mpg"]]
data_xy = df_xy.as_matrix()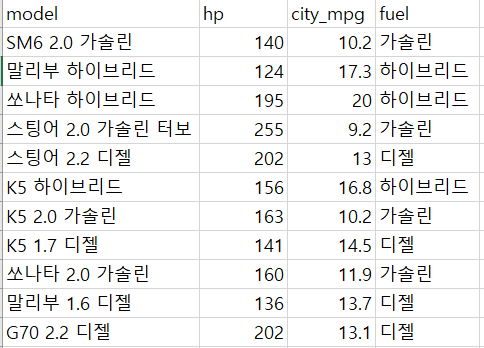
그다음에는 새롭게 분류할 데이터를 생성합니다.
hp = int(input('마력 입력 : '))
mpg = float(input('도심연비 입력 : '))*10
target = [hp, mpg]
dataset을 만들어 데이터를 분석하기 쉽게 만들어, 분류대상 및 범주를 생성합니다.
def data_set():
size = len(df_xy)
class_target = np.tile(target, (size, 1))
class_z = np.array(df_z)
return df_xy, class_target, class_z
dataset, class_target, class_z = data_set()유클리디안 거리 공식(Euclidean Distance)을 이용하여, 분류할 대상과 분류범주와의 거리를 구합니다.
그후, 가까운 값에따라 오름차순으로 정렬한 후 그 값에 따라 어떤 카테고리에 가까운지 분류합니다.
def classify(dataset, class_target, class_category, k):
diffMat = class_target - dataset
sqDiffMat = diffMat**2
row_sum = sqDiffMat.sum(axis=1)
distance = np.sqrt(row_sum)
sortDist = distance.argsort()
class_result = {}
for i in range(k):
c = class_category[sortDist[i]]
class_result[c] = class_result.get(c, 0) + 1
return class_result
이제 k값을 입력하는 코드와 함수를 호출하는 코드를 작성합니다.
k = int(input('k값을 입력해주세요 :'))
class_result = classify(data_xy, class_target, class_z, k) # classify()함수호출
print(class_result)
k값을 입력해주세요 :5
{'가솔린': 3, '디젤': 2}
위의 결과를 확인하였을 때, 내가 분류할 대상은 '가솔린' 연료 사용 카테고리에 가장 가까운 것을 알 수 있습니다.
def resultprint(class_result):
hev = Gas = die = 0
for c in class_result.keys():
if c == '하이브리드':
hev = class_result[c]
elif c =='가솔린':
Gas = class_result[c]
else :
die = class_result[c]
if hev > Gas and hev > die:
result = "분류대상은 하이브리드 입니다."
elif Gas > die and Gas > hev:
result = "분류대상은 가솔린 입니다"
elif die > hev and die > Gas:
result = "분류대상은 디젤 입니다."
else:
result = "k값을 변경해주세요."
return result
print(resultprint(class_result))
출력결과로는
분류대상은 가솔린 입니다.
라고 나올것입니다.
밑의 그림은 보기 쉽도록 시각화한 그래프입니다.

파란색 동그라미가 가솔린, 녹색 십자가가 하이브리드, 회색 엑스가 디젤입니다. 그리고 적색 별이 타켓입니다.
그래프는 밑에 있는 코드로 작성할 수 있습니다.
for c in range(len(df_xy)):
data_xy[c][1] = data_xy[c][1]/10
if df_z[c] == '가솔린':
plt.scatter(data_xy[c][0],data_xy[c][1],marker='o',color='b')
elif df_z[c] == '하이브리드':
plt.scatter(data_xy[c][0],data_xy[c][1],marker='+',color='g')
else:
plt.scatter(data_xy[c][0],data_xy[c][1],marker='x',color='gray')
plt.scatter(hp,mpg/10,marker='*',color='r')
plt.show()
출처 :
자동차 데이터 (https://auto.naver.com/car/mainList.nhn)
'Python 파이썬 > 머신러닝' 카테고리의 다른 글
| [파이썬, 텐서플로우] 단순회귀분석 (Simple Regression Analysis) (2) | 2019.11.21 |
|---|---|
| 군집 분석 (클러스터 분석) (0) | 2019.11.12 |
| K-최근접 이웃 알고리즘 (KNN) (0) | 2019.11.11 |
| 범주형 데이터 선형회귀 분석하기 (2) | 2019.11.06 |
| 넘파이 NumPy (0) | 2019.10.11 |